

This is the first in a series of articles examining the work of UiPath Research, a growing team of AI scientists, researchers, and engineers expanding the AI capabilities of the UiPath Business Automation Platform™. As the leader of this team, my colleagues and I are excited to share our work and discoveries.
The objective of the UiPath Research team is to build the best AI models for the enterprise. Our focus is not just to develop production-ready AI models, but continuously improving and expanding their capabilities as well.
As the first in the series, this article will focus on UiPath Helix Extractor 1.0, our new large language model (LLM) built for performing information extraction from documents.
What is Helix Extractor 1.0?
Documents are pervasive in business and are crucial for the running of key enterprise processes. They enable efficient information transfer between people and systems, standardizing processes and facilitating crucial record-keeping. However, due to their huge quantities and many forms (including structured, semi-structured, and unstructured) it has been a challenge for businesses to process masses of documents reliably, at speed and scale.
To resolve this, the UiPath Research team has developed Helix Extractor 1.0, which we revealed at UiPath AI Summit.
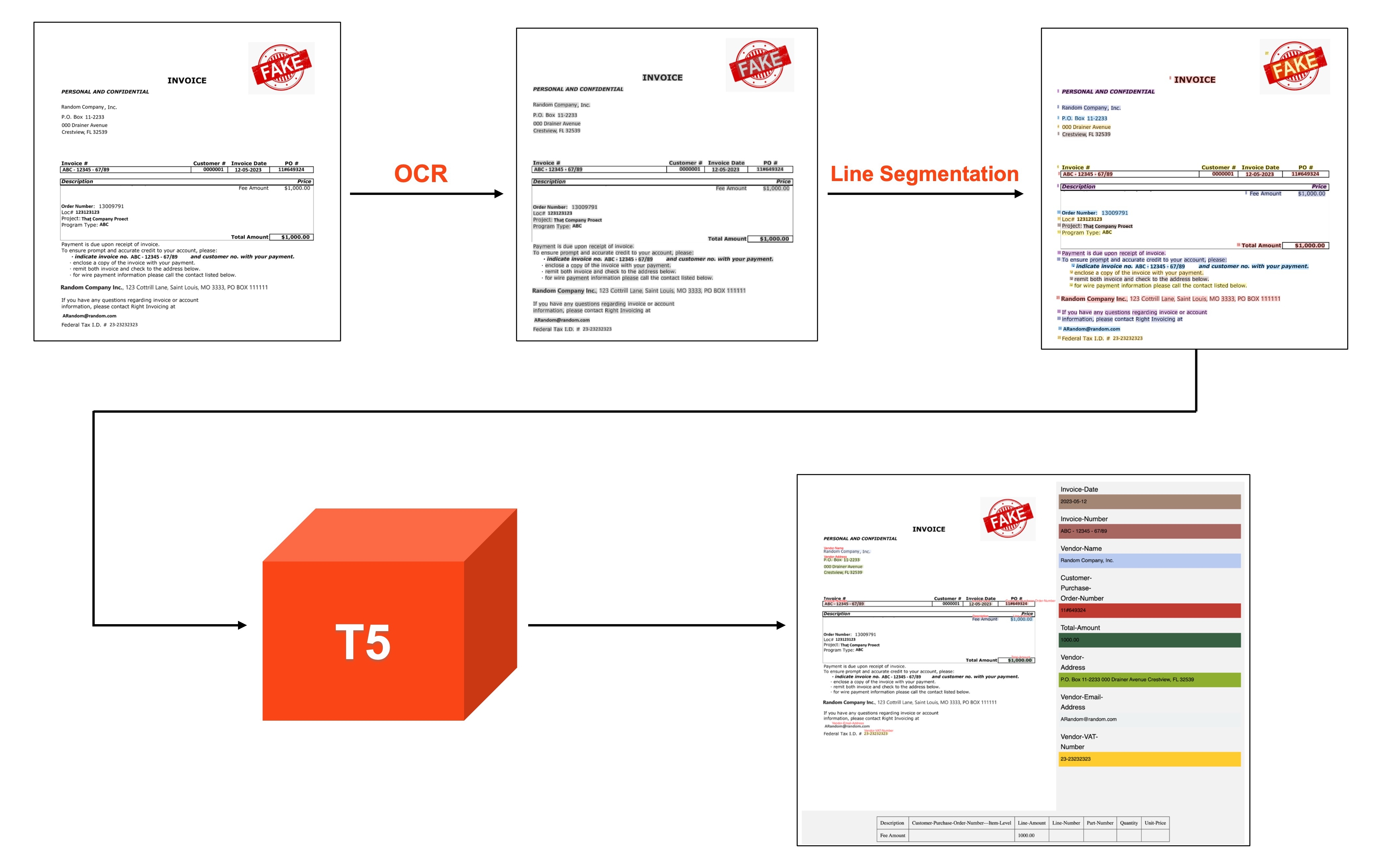
Helix Extractor 1.0 is the new foundational model of UiPath Document Understanding, our platform capability for intelligent document processing. It will help businesses process any document out-of-the-box, such as structured tax forms, invoices, purchase orders, or financial statements to name a few.
Developing Helix Extractor 1.0
In contrast to general-purpose generative AI models such as OpenAI’s GPT, we wanted to build a model for a specific task: information extraction from documents. However, even in prioritizing a specific task, we were confronted with many options for the underlying model architecture. Selecting between decoder-only and encoder-decoder architectures would inevitably require trade-offs between computational efficiency, task compatibility, and performance.
We experimented both with decoder-only and encoder-decoder architectures. We utilized a training dataset consisting of over 100,000 high-quality semi-structured documents, including invoices, receipts, forms, vehicle titles, purchase orders, etc. These documents were labeled for information extraction purposes. To prepare our training data, we sliced the documents into sequences up to a maximum sequence length, randomly selected a slice from each document, chose a random set of fields to be extracted from each slice, and created prompt/target pairs that included the document text, positional information, and the fields to be extracted.
Based on our results when fine-tuning decoder-only models including Mistral 7B and Llama-2-7b, we chose the Google FLAN-T5 XL model, an encoder-decoder architecture, as our base for fine-tuning Helix Extractor 1.0. We selected the instruction-tuned FLAN version of the T5 model as we observed that FLAN checkpoints consistently outperformed the non-FLAN T5 versions by a few points. This choice has a several advantages including:
-
Encoder-decoder models have demonstrated superior performance on fact-based tasks with a limited solution space, such as information extraction.
-
T5 offers pre-trained models in smaller parameter sizes, enabling easier experimentation before training larger versions of the T5 models.
-
The instruction tuning datasets of Flan-T5 are publicly accessible, making it convenient to utilize a small portion of that data during pre-training on our own internal data.

Prompt design
The previous generation of Document Understanding models used token classification based on encoder-only Transformers, classifying tokens to be a field from a fixed schema, and then applying post-processing logic to join the spans and apply field normalization based on the field type. With Helix Extractor 1.0, we moved to a prompt and completion approach where the model is only outputting a structured JSON. As a result, we had to develop a new method for performing attribution of the predicted field back to the document.
To achieve this, we embed positional tokens, created from each OCR box in the document, into the prompt, which provides the positional information to the model. An example prompt/target pair from our dataset looks like below:
Prompt:
"Given the following text on a semistructured document along with coordinates, extract the following fields : invoice-id , invoice-date , total, net-amount.
Text:
<CL1> <CX23> <CY25> Invoice. <CX25> <CY25> 235266 <CL2> <CX24><CY30> Date <CX34><CY32> 24/1/2023 ....."
Target:
{"invoice-id" : <CL1> <CX25> 235266 , "invoice-date" : <CL2> <CX34> 24/1/2023 .......}
And when extracting a table, we include the list of columns that need to be extracted in the prompt and decode all the values in the column along with their instance numbers. For ex:
Target:
{"line-amount" : {"0" : "<CX27><CY34> 20", "1": "<CX29><CY38> 25"} , "description" : {"0": "<CX16><CY32> Item1", "2": "<CX13><CY32> Item2"} .........}
As shown above, the special positional tokens enhance the model's understanding and grounding of the input. <CL> tokens represent line numbers determined by a line segmentation algorithm applied during pre-processing, while <CX> and <CY> denote page-wise normalized x and y coordinates of each word determined by OCR.
The tokens are added to our tokenizer and decoded in the output, enabling Helix Extractor 1.0 to attribute the response back to the input accurately. This positional grounding provides the reliability for information extraction tasks in the enterprise. To further improve the model's robustness to field names, we also incorporated data augmentation techniques like synonym replacement.
We experimented with incorporating image input using patch embeddings and layout information by updating the T5 attention to include 2D positional bias from the LayoutLMv3 model. However, we found that adding positional information directly within the prompt as shown above yielded better results.
Inference
To optimize inference and improve decoding throughput, we implemented several techniques. Decoding all fields in a single prompt can be time-consuming due to the auto-regressive nature of the process, especially when dealing with large tables and multi-valued fields. To address this, we divided the list of fields to extract from a document into buckets. We then run a separate prompt for each bucket in parallel and merge the responses from each prompt to obtain the final output. After experimenting with various inference engines, we found CTranslate2 to be the most user-friendly and efficient in terms of decoding throughput and integrating into our codebase. We assign confidence scores for fields based on the logit values for tokens associated with the field value.
Conclusion
UiPath Research introduces Helix Extractor 1.0, a fine-tuned LLM for information extraction from documents. We developed a novel approach to our prompt such that we can attribute the extracted fields back to the position on the document. We are experimenting with larger versions of the FLAN-T5 model and with decoder-only approaches. More research is needed to see if and how we can incorporate the document image pixels into the model.