
How to implement UiPath® Context Grounding

Introduction
In today's world, AI models are trained on vast public data, which means their responses might not always be aligned with the specific needs of a company. When relying on public data, there’s a risk of receiving irrelevant or inaccurate information for internal business contexts.
This is where UiPath Context Grounding comes into play. By enabling businesses to feed their own company data as the source of truth, within UiPath AI Trust Layer, UiPath ensures that the responses generated are highly relevant and trustworthy. Using a technique called retrieval augmented generation (RAG), it pulls from company-specific knowledge to deliver responses tailored to your use cases needs. In this tutorial, we'll explore how UiPath Context Grounding brings a new level of precision and trustworthiness to generative AI.
Context Grounding component architecture
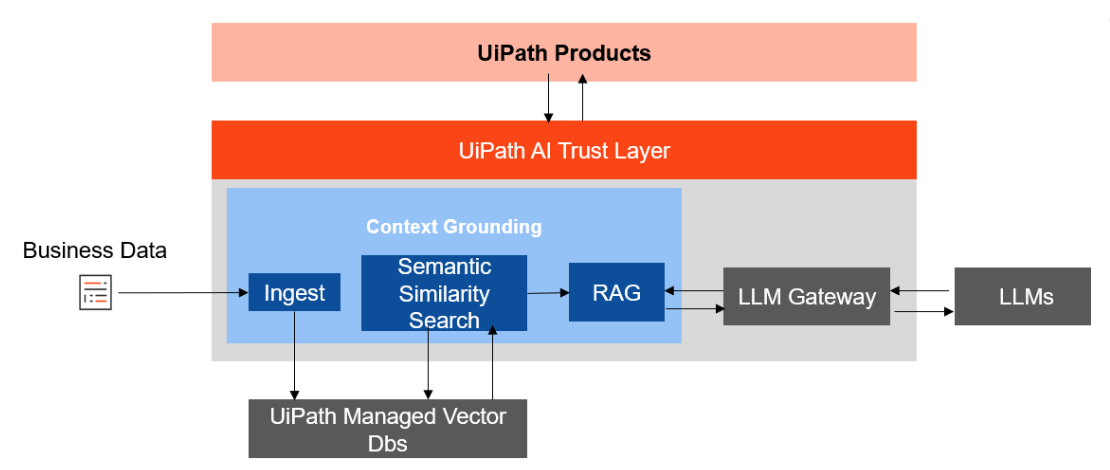
The UiPath Context Grounding architecture, as depicted in the image, centers around integrating company-specific data with generative AI models using a secure and efficient pipeline. It begins with ingesting business data, which is then transformed into vector embeddings and stored in an index in UiPath Context Grounding retrieval, augmented generation, LLM gate-way large language models managed vector databases for persistence and security. Context Grounding will then break down a user's query and apply a variety of semantic, hybrid, and other advanced search techniques to find and rank the most relevant pieces of information.
At the core of this architecture is the UiPath AI Trust Layer, which oversees the process, ensuring that data security and compliance are maintained while the system accesses and processes sensitive business information.
The Retrieval-Augmented Generation (RAG) technique leverages this retrieved data to generate context-aware responses. The LLM Gateway serves as a connection between the RAG module and the Large Language Models (LLMs), ensuring smooth interaction. This trust layer provides a secure boundary for organizations, reinforcing data governance while delivering precise AI-driven insights.
UiPath AI Trust Layer
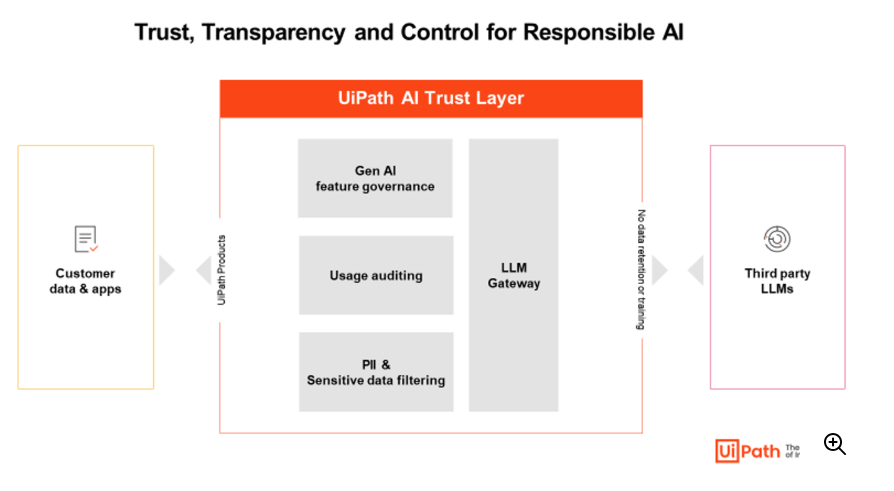
The AI Trust Layer plays a crucial role in safeguarding an organization's data while using retrieval augmented generation (RAG) with generative AI large language models (LLMs). When organizations integrate their proprietary data with generative AI, security becomes a top concern, as sensitive business information must remain protected. The trust layer ensures that only authorized data is used in the retrieval process, keeping confidential data secure from unauthorized access.
Additionally, it helps maintain compliance with industry regulations and data governance policies by controlling how data is processed and retrieved. By acting as a protective barrier, the trust layer ensures that while AI models generate insightful responses based on company data, the data itself remains secure and isolated, thus preserving privacy and trust within the organization's AI operations.
How to implement a UiPath Context Grounding
Now let’s see how we can easily implement a Context Grounding RAG solution on the UiPath Platform. Context Grounding supports UiPath Orchestrator Buckets and Integration Service Connections to Google Drive, Dropbox, and SharePoint.
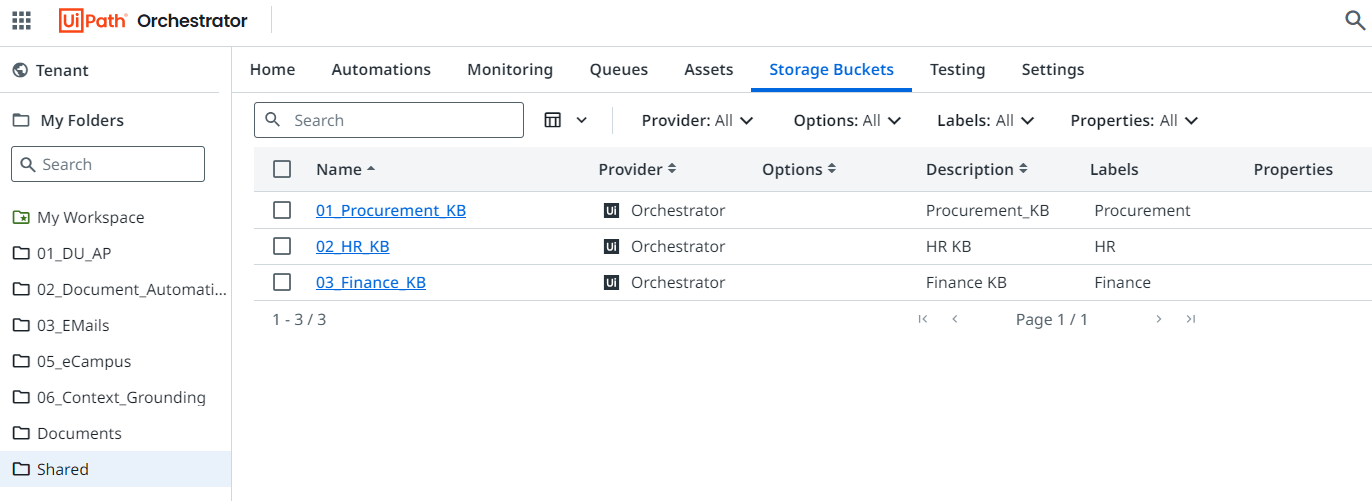
The first step is to identify what is the source of truth you want to use for your index. You can create separate storage buckets for different categories of data, which will enhance accuracy by enabling more precise selection of the right index during information retrieval.
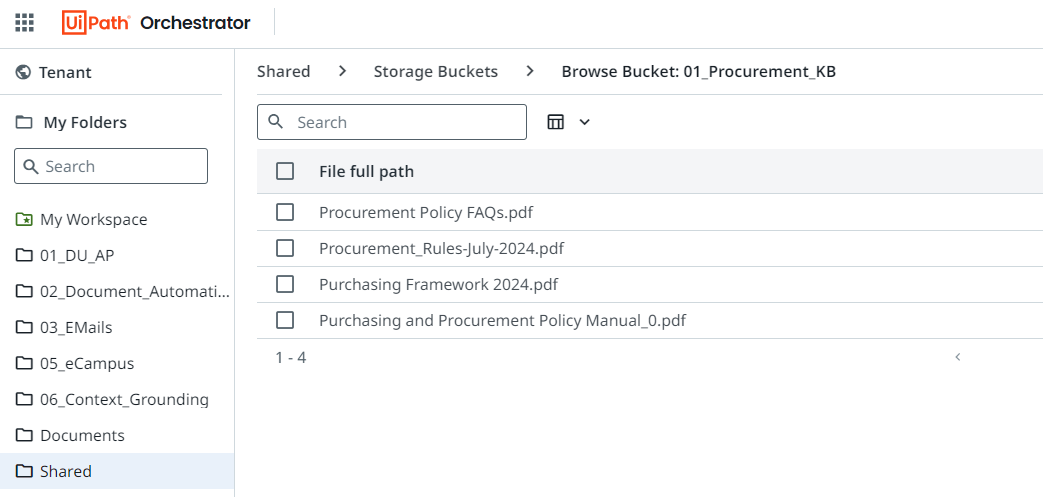
Next, upload your documents to the designated storage buckets. Currently, the platform supports PDF, CSV, JSON, XLS, TXT, and DOCX file formats, with plans to include additional formats in future updates. In this instance, I’ve utilized the organization’s various procurement policies.
Next, create a GenAI Activities Connection in the Integration Service. Choose the folder where you want to add the connector, and then add the UiPath GenAI Activities connector.
You don’t need an OpenAI or Google's GenAI subscription—UiPath manages the integration for you. While Context Grounding does not charge for data ingestion, AI units will be consumed when querying. For more details, visit UiPath documentation portal.
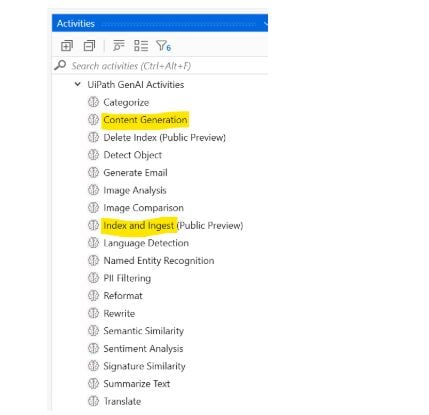
Once you've added the GenAI connection, you'll see the following activities under the UiPath GenAI Activity set. The three highlighted below are essential for implementing the Context Grounding solution:
Index and Ingest: This activity creates a vector database (Index) from your source data. The output will be the newly created vector database. This needs to be run anytime new data is added to the storage bucket to keep the index up to date.
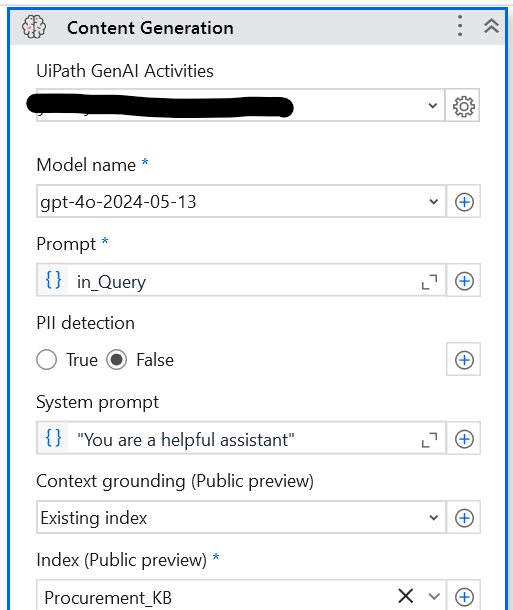
Content Generation: Here, you pass the base LLM model (such as OpenAI GPT or Google Gemini) and select the appropriate index created in the previous step.
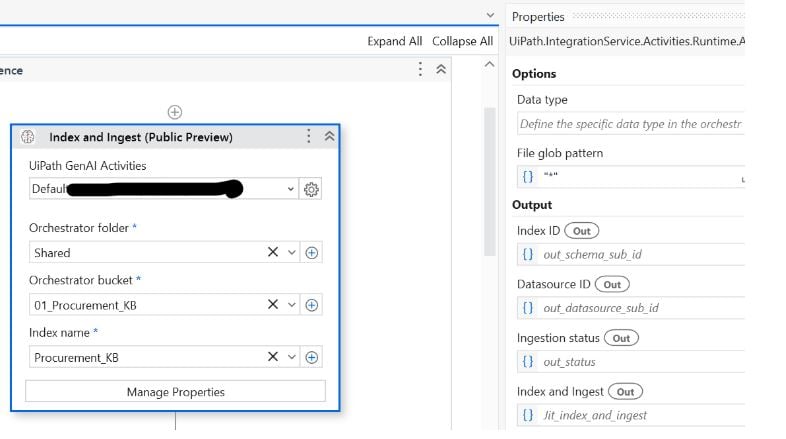
When executing the Index and Ingest activity, you'll need to select the correct folder name, bucket name, and provide an Index name. If the storage bucket contains multiple file types, choose the appropriate type and run the activity separately for each. If there are changes to the source data, you will need to rerun this activity to retrain the Index accordingly.
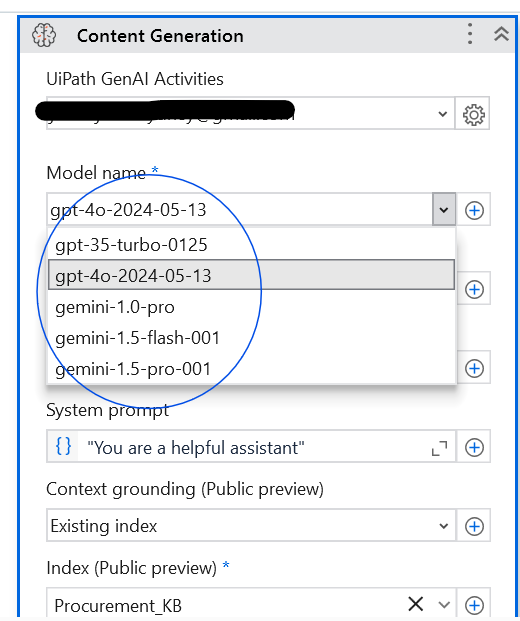
The next step, Content Generation, is crucial for this implementation. Choose the base LLM model (either OpenAI GPT or Google Gemini) and select the pre-existing Index for retrieval augmented generation (RAG). Additionally, provide the prompt as an argument. The output will be used as another argument when integrating with UiPath Apps (which I’ve used as the user interface in this solution).
If needed, you can also apply PII detection to filter out any personally identifiable information from the output. If a user wants to execute Context Grounding on a single file and doesn't need that to be persisted in an index, they can do so using file resource instead of an existing index.
When designing your solution with UiPath Apps for user interaction, you'll need at least two arguments as described below. After completing your workflow, publish the package to the Orchestrator and install the process.

Now, let's create an app in UiPath Apps.
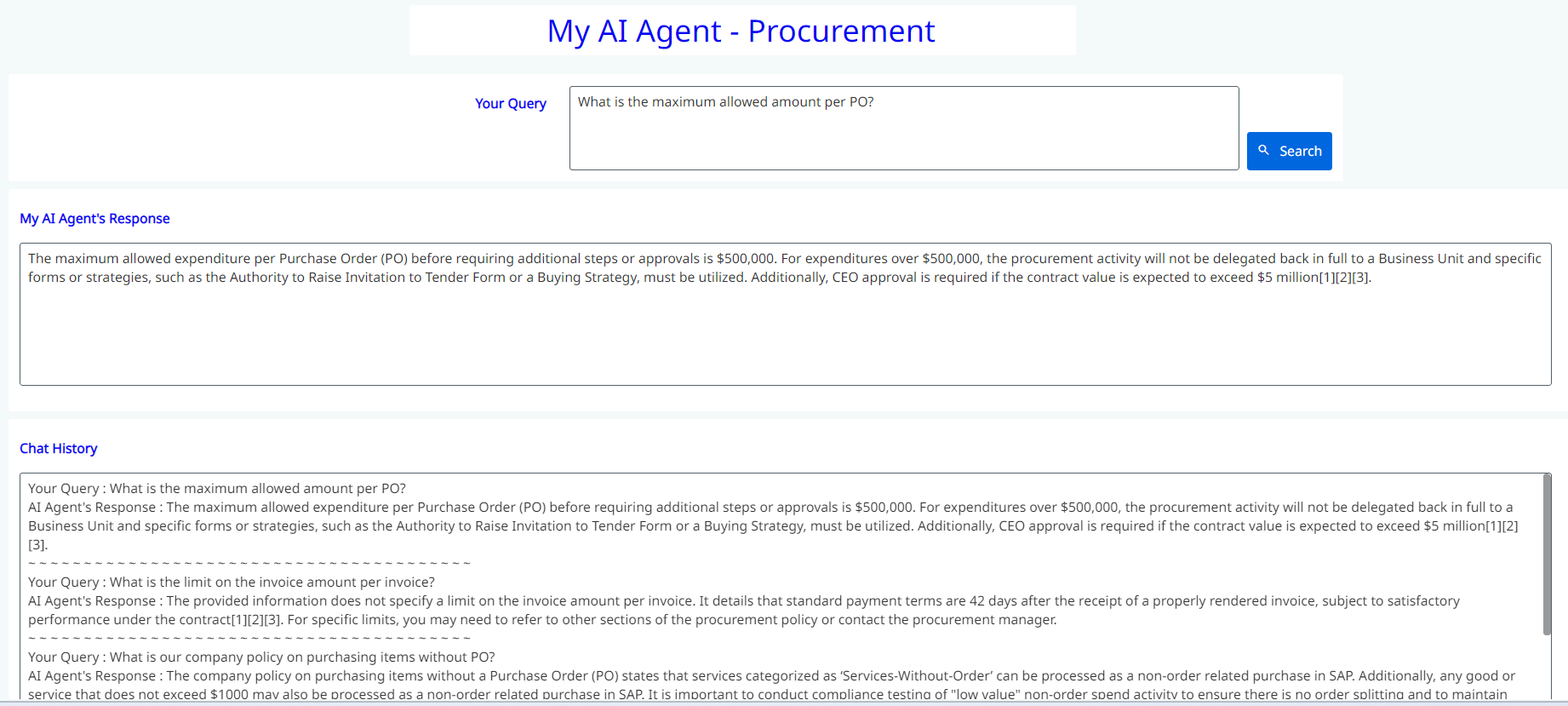
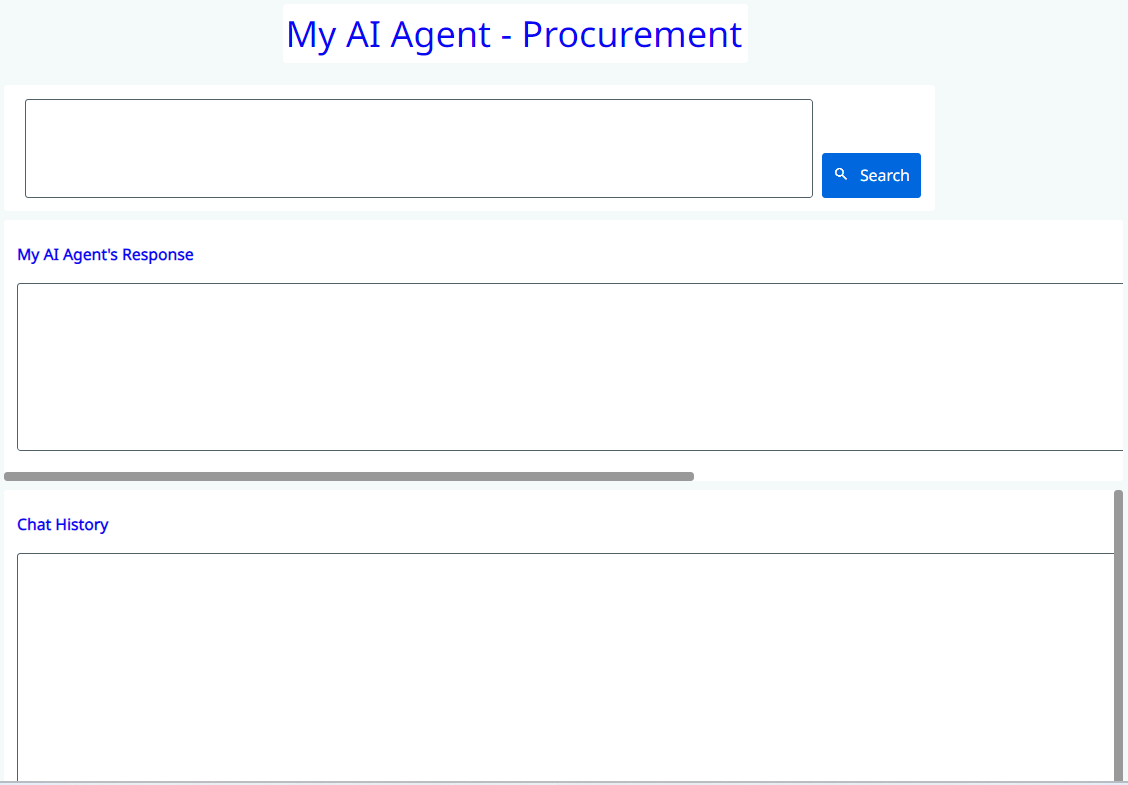
This is a straightforward app I created for this implementation: It includes one text box for entering the query, a search button, another text box for displaying the response, and a final text box for showing the history.
Next, add the process we previously published from Studio. This will establish the interaction between the app and the underlying automation.
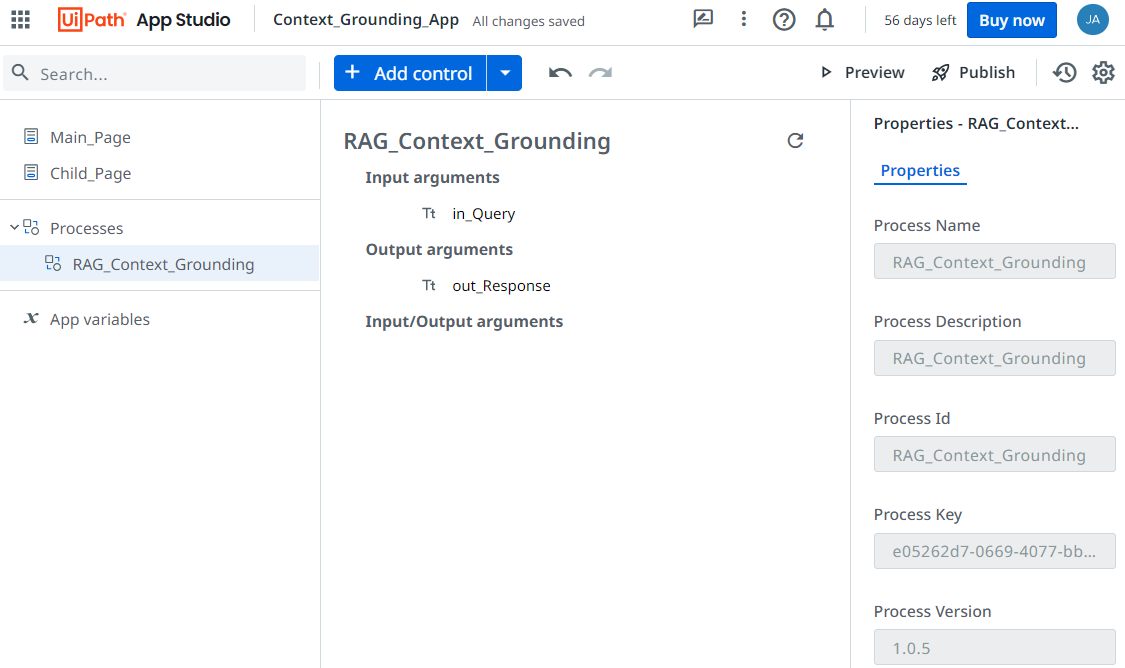
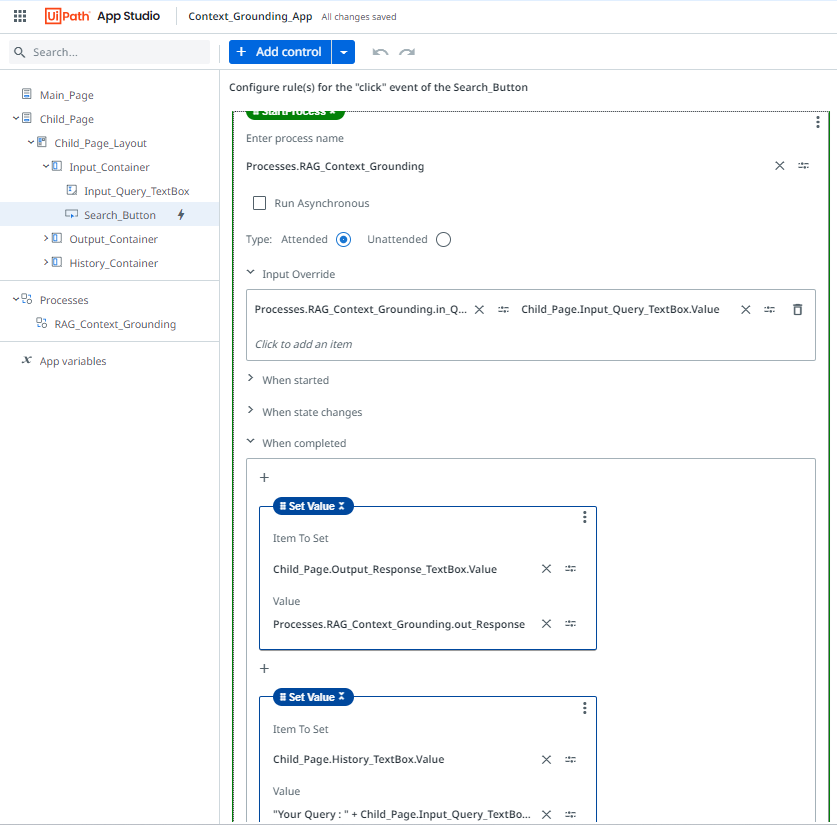
The rule defined under the search button controls the interaction between the app and the process. When the user clicks the search button, it triggers the process and passes two arguments. The responses returned will be displayed in the response text box.
That’s it! Below, you can see the process in action. Simply enter your question based on the source data, and you’ll receive an answer from your own document. The response is derived solely from the data you provided as the source of truth, not from publicly available datasets. Isn’t that fascinating? You can continue asking questions directly here without needing to email your P2P team or anyone else in your organization. Once you publish the app, you can share the URL with your employees, allowing them to use it directly.
Conclusion
UiPath Context Grounding offers a powerful way to integrate company-specific data with generative AI, ensuring that the responses generated are relevant, accurate, and secure. By leveraging the RAG technique, organizations can enhance their AI capabilities while maintaining control over their proprietary information through the AI Trust Layer.
With seamless integration into the UiPath Platform, setting up storage, indexing data, and managing AI workflows becomes an intuitive process, allowing businesses to harness the full potential of AI-driven insights without compromising data security or integrity.
Here are some links to explore more about this topic:
Topics:
AI
Solution Architect, Tech Mahindra
Related articles



Get articles from automation experts in your inbox
SubscribeGet articles from automation experts in your inbox
Sign up today and we'll email you the newest articles every week.
Thank you for subscribing!
Thank you for subscribing! Each week, we'll send the best automation blog posts straight to your inbox.