UiPath Document Understanding과 OCR 연계 활용

지난 포스트에서는 OCR기술의 간단한 소개와 더불어 장단점을 살펴 보았습니다.
오늘은 UiPath Document Understanding (도큐멘트 언더스탠딩)의 OCR 활용에 대해 알아보겠습니다. UiPath Document Understanding은 데이터 처리 및 분석 전 단계인 데이터 디지털화 작업에서 RPA와 AI 그리고 OCR을 함께 활용합니다.
이를 통해 정형, 비정형 데이터를 모두 처리하면서 데이터 테이블, 체크 박스, 수기 및 서명 같은 다양한 데이터 객체를 다룰 수 있습니다.
Document Understanding은 지금까지 자동화가 어려웠던, 프로세스가 복잡한 업무도 end-to-end 처리할 수 있다는 큰 장점을 갖고 있습니다. 또한 정확도 높은 문서 처리, 높은 운영 효율성과 인력에 의한 오류 방지로 업무 자동화의 품질을 크게 높여줍니다.
많은 이들이 Document Understanding과 OCR을 같은 기술이라고 생각하지만, Document Understanding이 문서 텍스트 디지털화 작업에 OCR을 이용한다는 것이 더 정확한 표현일 것 같습니다.
대부분의 OCR 엔진은 데이터 추출 기능이 하나로 통합되어 있지만, UiPath는 이 둘을 분리해 운영합니다. 둘이 분리되어 있기 때문에 사용자는 필요에 따라 다른 OCR 엔진을 사용해 확장성과 정확도를 높일 수 있는 선택권을 가질 수 있습니다. 작아 보이지만 OCR 이 적용되는 업무 특성에 따라 큰 차이를 만드는 요소이죠.
UiPath Document Understanding의 OCR 활용
아래 그림은 Document Understanding의 업무 흐름도입니다. 텍사노미 (인식할 문서, 데이터 항목 및 형태를 사전에 정의한 작업) 적용을 시작으로 데이터 디지털화, 분류와 추출 그리고 내보내기 순서로 진행합니다. 단계별 작업을 하나씩 살펴보겠습니다.
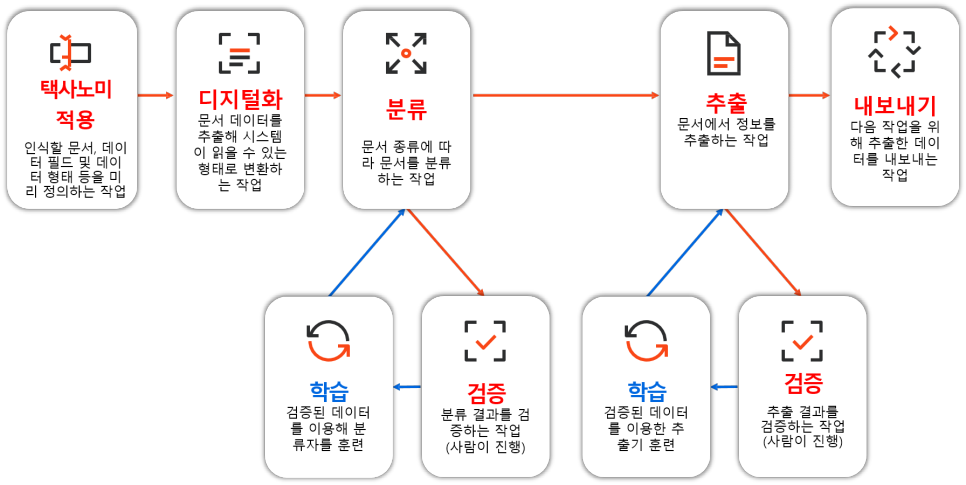
UiPath Document Understanding 흐름도
OCR은 텍사노미가 워크플로우에 적용되고 추출 대상 파일과 데이터 정의 작업이 완료 된 UiPath Document Understanding프로세스 초기 단계에서 실행됩니다. Document Understanding은 OCR (UiPath및 타사 OCR 엔진 사용 가능)을 사용해 텍스트를 인식하고 RPA로봇이 읽을 수 있는 디지털 형태로 변환합니다. 그 다음 사전 정리된 목록에 따라 문서를 분류하고, 데이터를 추출해 지정된 저장 공간으로 내보냅니다. 저장 공간으로 보내기 전에 사람이 검증하는 단계를 추가할 수도 있습니다.
앞에서 잠깐 언급한 것처럼 Document Understanding은 분류와 추출 단계에서 AI 기술을 활용합니다. 고객이 자체 개발하거나 기본 제공된 UiPath 머신러닝 모델을 활용해 문서 분류 및 데이터 추출 작업을 학습시키고 인력에 의한 검증을 통해 정확도를 높여갈 수 있습니다.
문서 분류 (Classification)
머신러닝 기술을 이용하는 분류 (Classification) 작업을 살펴보겠습니다. OCR을 통해 디지털화된 문서는 미리 정리된 기준에 따라 아래 그림과 같이 분류될 수 있습니다. 이때, 3가지의 분류자 (Classifier)가 사용됩니다.
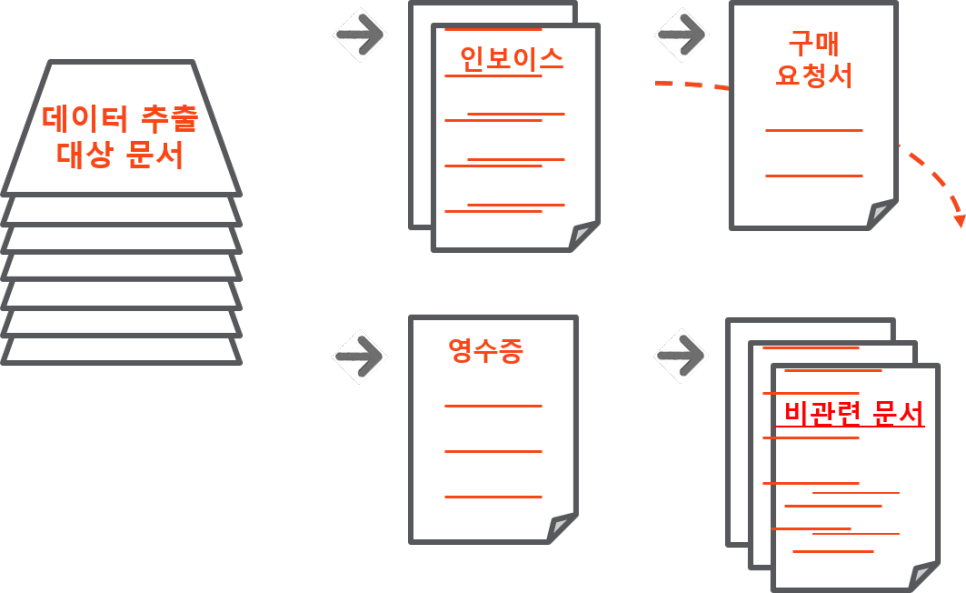
문서 분류 (Classification) 작업
1) 키워드 분류자 (Keyword Classifier): 사람이 분류 대상 문서에 포함된 키워드를 정의하는 방법입니다. 위 그림처럼 ‘인보이스’ 및 ‘영수증’ 등 키워드를 정의하면 이에 따라 문서를 나누는 방법입니다.
2) 지능형 키워드 분류자 (Intelligent Keyword Classifier): UiPath Tool에 샘플 문서를 제공해 훈련시키면 툴 스스로 키워드를 인식해 저장했다가 입력되는 문서 키워드의 벡터와 비교해서 문서를 분류하는 방식입니다.
3) 머신러닝 분류자 (Machine Learning Classifier): “간단하게 알아보는 AI기술과 UiPath AI Center” 포스트에서 논의한 머신러닝 모델을 이용해 분류하는 방식입니다. 물론 이 방법을 사용하기 위해서는 머신러닝 모델 확보와 학습 과정이 선행되어야 합니다.
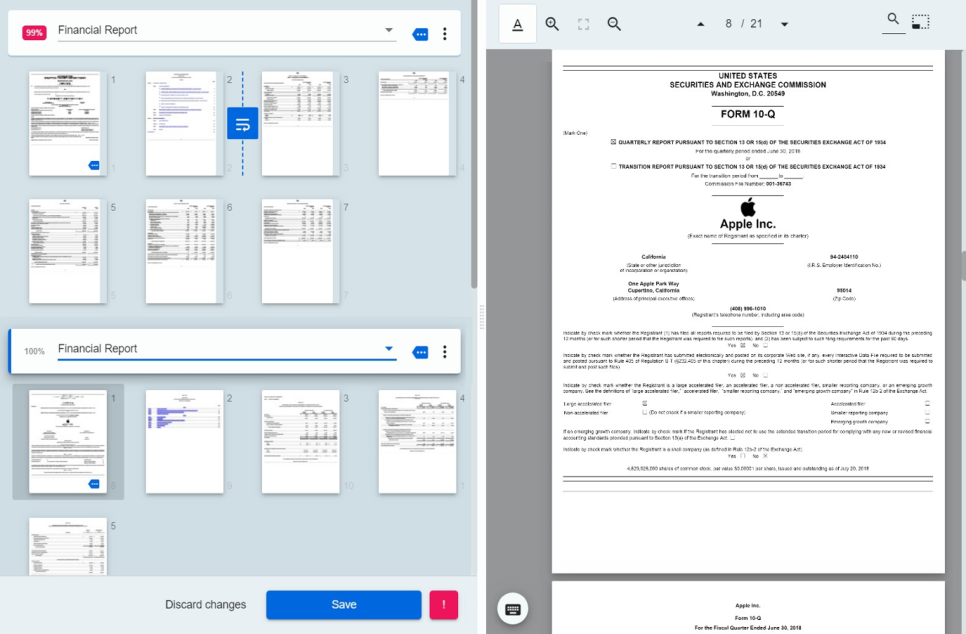
문서 분류 결과 검증 화면
문서 분류 작업에는 필요에 따라 사람에 의한 검증 작업을 추가할 수 있습니다. 아래는 검증자가 보는 화면입니다. 화면 왼쪽에 분류된 문서의 각 페이지를 표시하고 어떤 기준으로 어떻게 분류했는지 보여줍니다. 이 내용을 토대로 검증자는 잘못된 페이지 구성이나 분류 결과를 조정할 수 있습니다.
데이터 추출 (Extraction)
문서 분류 다음은 데이터 추출 작업입니다. UiPath Document Understanding은 규칙 (Rule) 기반과 머신러닝 기반의 2개 추출 방식을 제공하고 규칙 기반 방식은 다시 정규 표현식, 폼 그리고 지능형 폼 방식으로 나눠집니다. 규칙 기반과 머신러닝 방식을 함께 사용하는 하이브리드 모델도 가능합니다.

데이터 추출 방식
1) 정규표현식 추출기 (Extractor): 가장 단순한 방식으로 문서에서 인식된 데이터를 그대로 추출하는 기능입니다.
2) 폼 추출기 (Extractor): 세금계산서, 인보이스 등과 같이 고정된 구성을 가진 문서에서 데이터를 추출하는 기능입니다.
3) 지능형 폼 추출기 (Extractor): 폼 추출자와 비슷하지만 문서에 서명 등이 있는지를 확인할 수 있습니다.
분류 작업과 동일하게 데이터 추출 단계에서도 머신러닝 모델에 의한 학습과 사람에 의한 검증이 가능합니다. 아래는 검증자가 보는 화면입니다. 화면 왼쪽이 추출된 데이터 항목이고 우측이 원본 문서의 구성입니다. 특정 데이터 항목을 선택하면 그 항목이 문서의 어느 영역에서 추출되었는지 하이라이트로 표시해주기 주기 때문에 쉽게 파악할 수 있습니다. 추출된 값이 잘못되었거나 추출되지 않은 항목이 있다면, 검증자가 바로 추가 및 수정할 수 있습니다.
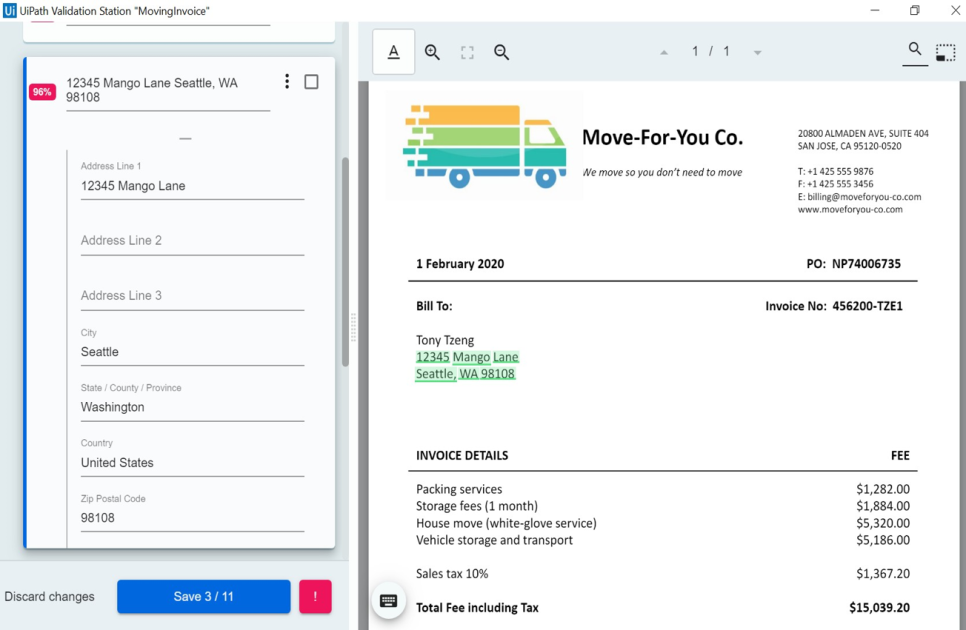
데이터 추출 결과 검증 화면
UiPath Document Understanding 연계 활용으로 OCR의 활용도가 더욱 넓어지고 기존 업무의 정확도와 효율성을 높일 수 있습니다. 다음 포스트에서는 UiPath AI 컴퓨터 비전과 OCR 연계 활용에 대해 정리해 보겠습니다.
Team, UiPath Korea
Related articles



Get articles from automation experts in your inbox
SubscribeGet articles from automation experts in your inbox
Sign up today and we'll email you the newest articles every week.
Thank you for subscribing!
Thank you for subscribing! Each week, we'll send the best automation blog posts straight to your inbox.